
内容介绍
资深大数据专家多年实战经验总结,拒绝晦涩,开启大数据与机器学习妙趣之旅。以降低学习曲线和阅读难度为宗旨,系统讲解统计学、数据挖掘算法、实际应用案例、数据价值与变现,以及高级拓展技能,并清晰勾勒出大数据技术路线与产业蓝图。《白话大数据与机器学习》共分18章。用通俗易懂的语言,结合大量案例与漫画,不枯燥,实用、接地气。
第1~5章,这部分是大数据入门所需的系统性知识,剖析大数据产业、数据与信息算法等的关系,妙解数学基础(排列组合、概率、统计与分布),以及指标化运营及体系构建。这部分补足读者的产业与相关概念认知,以及所需的数学知识。为下面的数据挖掘算法的理解与应用夯实基础。
第6~8章,这部分介绍数据挖掘基础知识与算法,讲解了与数据息息相关的信息论,重点讲解了:多维向量空间(向量和维度、矩阵及其计算、上卷和下钻);
回归(线性回归、残差分析、拟合相关问题);
聚类(K-Means算法、有趣模式、孤立点、层次与密度聚类,聚类的评估等);
分类(朴素贝叶斯、决策树归纳、随机森林、隐马尔科夫模型、SVM、遗传算法)。
第11~18章,这部分介绍生产应用与高级扩展。其中第11~15章介绍生产应用实践,涵盖关联分析、用户画像、推荐算法、文本挖掘、人工神经网络。这些也是工业界和学术界研究的热点。第16章讲解了著名的大数据框架及其安装与配置,如Hadoop、Spark、Cassandra、PrestoDB。第17章从速度与稳定性维度介绍了大数据系统的架构与调优。第18章则从数据运营、评估、展现与变现场景层面进行了解读。
章节目录
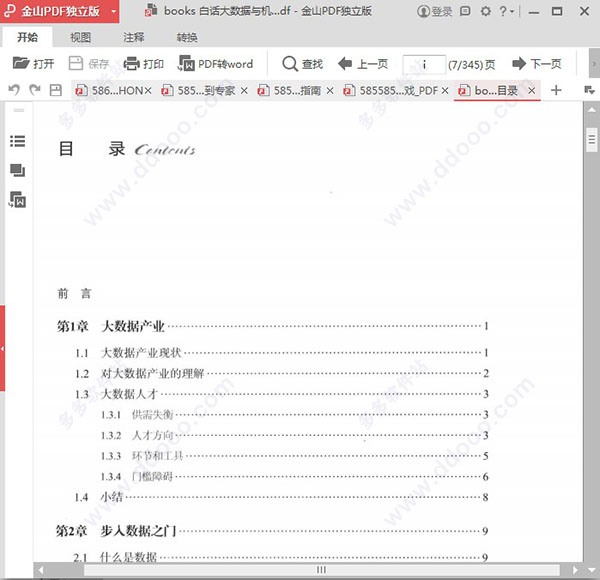
第1章大数据产业11.1大数据产业现状11.2对大数据产业的理解21.3大数据人才31.3.1供需失衡31.3.2人才方向31.3.3环节和工具51.3.4门槛障碍61.4小结8第2章步入数据之门92.1什么是数据92.2什么是信息102.3什么是算法122.4统计、概率和数据挖掘132.5什么是商业智能132.6小结14第3章排列组合与古典概型153.1排列组合的概念163.1.1公平的决断——扔硬币163.1.2非古典概型173.2排列组合的应用示例183.2.1双色球183.2.2购车摇号203.2.3德州扑克213.3小结25第4章统计与分布274.1加和值、平均值和标准差274.1.1加和值284.1.2平均值294.1.3标准差304.2加权均值324.2.1混合物定价324.2.2决策权衡344.3众数、中位数354.3.1众数364.3.2中位数374.4欧氏距离374.5曼哈顿距离394.6同比和环比414.7抽样434.8高斯分布454.9泊松分布494.10伯努利分布524.11小结54第5章指标555.1什么是指标555.2指标化运营585.2.1指标的选择585.2.2指标体系的构建625.3小结63第6章信息论646.1信息的定义646.2信息量656.2.1信息量的计算656.2.2信息量的理解666.3香农公式686.4熵706.4.1热力熵706.4.2信息熵726.5小结75第7章多维向量空间767.1向量和维度767.1.1信息冗余777.1.2维度797.2矩阵和矩阵计算807.3数据立方体837.4上卷和下钻857.5小结86第8章回归878.1线性回归878.2拟合888.3残差分析948.4过拟合998.5欠拟合1008.6曲线拟合转化为线性拟合1018.7小结104第9章聚类1059.1K-Means算法1069.2有趣模式1099.3孤立点1109.4层次聚类1109.5密度聚类1139.6聚类评估1169.6.1聚类趋势1179.6.2簇数确定1199.6.3测定聚类质量1219.7小结124第10章分类12510.1朴素贝叶斯12610.1.1天气的预测12810.1.2疾病的预测13010.1.3小结13210.2决策树归纳13310.2.1样本收集13510.2.2信息增益13610.2.3连续型变量13710.3随机森林14010.4隐马尔可夫模型14110.4.1维特比算法14410.4.2前向算法15110.5支持向量机SVM15410.5.1年龄和好坏15410.5.2“下刀”不容易15710.5.3距离有多远15810.5.4N维度空间中的距离15910.5.5超平面怎么画16010.5.6分不开怎么办16010.5.7示例16310.5.8小结16410.6遗传算法16410.6.1进化过程16410.6.2算法过程16510.6.3背包问题16510.6.4极大值问题17310.7小结181第11章关联分析18311.1频繁模式和Apriori算法18411.1.1频繁模式18411.1.2支持度和置信度18511.1.3经典的Apriori算法18711.1.4求出所有频繁模式19011.2关联分析与相关性分析19211.3稀有模式和负模式19311.4小结194第12章用户画像19512.1标签19512.2画像的方法19612.2.1结构化标签19612.2.2非结构化标签19812.3利用用户画像20312.3.1割裂型用户画像20312.3.2紧密型用户画像20412.3.3到底“像不像”20412.4小结205第13章推荐算法20613.1推荐思路20613.1.1贝叶斯分类20613.1.2利用搜索记录20713.2User-basedCF20913.3Item-basedCF21113.4优化问题21513.5小结217第14章文本挖掘21814.1文本挖掘的领域21814.2文本分类21914.2.1Rocchio算法22014.2.2朴素贝叶斯算法22314.2.3K-近邻算法22514.2.4支持向量机SVM算法22614.3小结227第15章人工神经网络22815.1人的神经网络22815.1.1神经网络结构22915.1.2结构模拟23015.1.3训练与工作23115.2FANN库简介23315.3常见的神经网络23515.4BP神经网络23515.4.1结构和原理23615.4.2训练过程23715.4.3过程解释24015.4.4示例24015.5玻尔兹曼机24415.5.1退火模型24415.5.2玻尔兹曼机24515.6卷积神经网络24715.6.1卷积24815.6.2图像识别24915.7深度学习25515.8小结256第16章大数据框架简介25716.1著名的大数据框架25716.2Hadoop框架25816.2.1MapReduce原理25916.2.2安装Hadoop26116.2.3经典的WordCount26416.3Spark框架26916.3.1安装Spark27016.3.2使用Scala计算WordCount27116.4分布式列存储框架27216.5PrestoDB——神奇的CLI27316.5.1Presto为什么那么快27316.5.2安装Presto27416.6小结277第17章系统架构和调优27817.1速度——资源的配置27817.1.1思路一:逻辑层面的优化27917.1.2思路二:容器层面的优化27917.1.3思路三:存储结构层面的优化28017.1.4思路四:环节层面的优化28017.1.5资源不足28117.2稳定——资源的可用28217.2.1借助云服务28217.2.2锁分散28217.2.3排队28317.2.4谨防“雪崩”28317.3小结285第18章数据解读与数据的价值28618.1运营指标28618.1.1互联网类型公司常用指标28718.1.2注意事项28818.2AB测试28918.2.1网页测试29018.2.2方案测试29018.2.3灰度发布29218.2.4注意事项29318.3数据可视化29518.3.1图表29518.3.2表格29918.4多维度——大数据的灵魂29918.4.1多大算大29918.4.2大数据网络30018.4.3去中心化才能活跃30118.4.4数据会过剩吗30218.5数据变现的场景30318.5.1数据价值的衡量的讨论30318.5.2场景1:征信数据30718.5.3场景2:宏观数据30818.5.4场景3:画像数据30918.6小结310附录AVMwareWorkstation的安装311附录BCentOS虚拟机的安装方法314附录CPython语言简介318附录DScikit-learn库简介323附录EFANNforPython安装324附录F群众眼中的大数据325写作花絮327参考文献329
使用说明
1、下载并解压,得出pdf文件2、如果打不开本文件,请务必下载pdf阅读器
3、安装后,在打开解压得出的pdf文件
4、双击进行阅读>
下载仅供下载体验和测试学习,不得商用和正当使用。
下载体验