
内容介绍
《数据科学实战》脱胎于哥伦比亚大学“数据科学导论”课程的教学讲义,它界定了数据科学的研究范畴,是一本注重人文精神,多角度、全方位、深入介绍数据科学的实用指南,堪称大数据时代的实战宝典。本书旨在让读者能够举一反三地解决重要问题,内容包括:数据科学及工作流程、统计模型与机器学习算法、信息提取与统计变量创建、数据可视化与社交网络、预测模型与因果分析、数据预处理与工程方法。另外,本书还将带领读者展望数据科学未来的发展。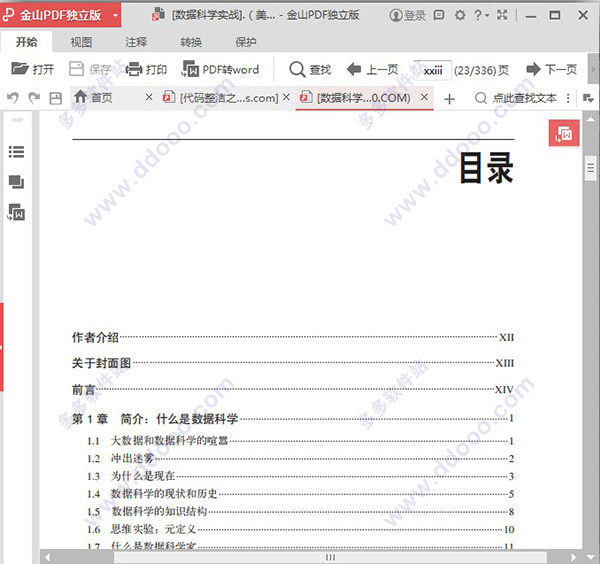
章节目录
作者介绍 XII关于封面图 XIII前言 XIV第1章 简介:什么是数据科学1.1 大数据和数据科学的喧嚣1.2 冲出迷雾1.3 为什么是现在1.4 数据科学的现状和历史1.5 数据科学的知识结构1.6 思维实验:元定义1.7 什么是数据科学家1.7.1 学术界对数据科学家的定义1.7.2 工业界对数据科学家的定义第2章 统计推断、探索性数据分析和数据科学工作流程2.1 大数据时代的统计学思考2.1.1 统计推断2.1.2 总体和样本2.1.3 大数据的总体和样本2.1.4 大数据意味着大胆的假设2.1.5 建模2.2 探索性数据分析2.2.1 探索性数据分析的哲学2.2.2 练习:探索性数据分析2.3 数据科学的工作流程2.4 思维实验:如何模拟混沌2.5 案例学习:RealDirect2.5.1 RealDirect是如何赚钱的2.5.2 练一练:RealDirect公司的数据策略第3章 算法3.1 机器学习算法3.2 三大基本算法3.2.1 线性回归模型3.2.2 k 近邻模型(k-NN)3.2.3 k 均值算法3.3 练习:机器学习算法基础3.4 总结3.5 思维实验:关于统计学家的自动化第4章 垃圾邮件过滤器、朴素贝叶斯与数据清理4.1 思维实验:从实例中学习4.1.1 线性回归为何不适用4.1.2 k 近邻效果如何4.2 朴素贝叶斯模型4.2.1 贝叶斯法则4.2.2 个别单词的过滤器4.2.3 直通朴素贝叶斯4.3 拉普拉斯平滑法4.4 对比朴素贝叶斯和k 近邻4.5 Bash代码示例4.6 网页抓取:API和其他工具4.7 Jake的练习题:文章分类问题中的朴素贝叶斯模型第5章 逻辑回归5.1 思维实验5.2 分类器5.2.1 运行时间5.2.2 你自己5.2.3 模型的可解释性5.2.4 可扩展性5.3 逻辑回归:一个来自M6D 的真实案例研究5.3.1 点击模型5.3.2 模型背后5.3.3 α和β 的参数估计5.3.4 牛顿法5.3.5 随机梯度下降法5.3.6 操练5.3.7 模型评价5.4 练习题第6章 时间戳数据与金融建模6.1 Kyle Teague与GetGlue公司6.2 时间戳6.2.1 探索性数据分析(EDA)6.2.2 指标和新变量6.2.3 下一步怎么做6.3 轮到Cathy O'Neill了6.4 思维实验6.5 金融建模6.5.1 样本期内外以及因果关系6.5.2 金融数据处理6.5.3 对数收益率6.5.4 实例:标准普尔指数6.5.5 如何衡量波动率6.5.6 指数平滑法6.5.7 金融模型的反馈6.5.8 聊聊回归模型6.5.9 先验信息量6.5.10 一个小例子6.6 练习:GetGlue分享的时间戳数据第7章 从数据到结论7.1 William Cukierski7.1.1 背景介绍:数据科学竞赛7.1.2 背景介绍:众包模式7.2 Kaggle模式7.2.1 Kaggle的参赛者7.2.2 Kaggle的客户7.3 思维实验:关于作业自动评分系统7.4 特征选择7.4.1 例子:留住用户7.4.2 过滤型7.4.3 包装型7.4.4 决策树与嵌入型变量选择7.4.5 熵7.4.6 决策树算法7.4.7 如何在决策树模型中处理连续性变量7.4.8 随机森林7.4.9 用户黏性:模型的预测能力与可解释性7.5 David Huffaker:谷歌社会学研究的新方法7.5.1 从描述性统计到预测模型7.5.2 谷歌的社交研究7.5.3 隐私保护7.5.4 思维实验:如何消除用户的顾虑第8章 构建面向大量用户的推荐引擎8.1 一个真实的推荐引擎8.1.1 最近邻算法回顾8.1.2 最近邻模型的已知问题8.1.3 超越近邻模型:基于机器学习的分类模型8.1.4 高维度问题8.1.5 奇异值分解(SVD)8.1.6 关于SVD的重要特性8.1.7 主成分分析(PCA)8.1.8 交替最小二乘法8.1.9 固定矩阵V,更新矩阵U8.1.10 关于这些算法的一点思考8.2 思维实验:如何过滤模型中的泡沫8.3 练习:搭建自己的推荐系统第9章 数据可视化与欺诈侦测9.1 数据可视化的历史9.1.1 Gabriel Tarde9.1.2 Mark 的思维实验9.2 到底什么是数据科学9.2.1 Processing9.2.2 Franco Moretti9.3 一个数据可视化的方案实例9.4 Mark 的数据可视化项目9.4.1 《纽约时报》大厅里的可视化:Moveable Type9.4.2 屏幕上的生命:Cascade可视化项目9.4.3 Cronkite广场项目9.4.4 eBay与图书网购9.4.5 公共剧场里的"莎士比亚机"9.4.6 这些展览的目的是什么9.5 数据科学和风险9.5.1 关于Square公司9.5.2 支付风险9.5.3 模型效果的评估问题9.5.4 建模小贴士9.6 数据可视化在Square9.7 Ian的思维实验9.8 关于数据可视化第10章 社交网络与数据新闻学10.1 Morning Analytics与社交网络10.2 社交网络分析10.3 关于社交网络分析的相关术语10.3.1 如何衡量向心性10.3.2 使用哪种向心性测度10.4 思维实验10.5 Morningside Analytics10.6 从统计学的角度看社交网络分析10.6.1 网络的表示方法与特征值向心度10.6.2 随机网络的第一个例子:Erdos-Renyi模型10.6.3 随机网络的第二个例子:指数随机网络图模型10.7 数据新闻学10.7.1 关于数据新闻学的历史回顾10.7.2 数据新闻报告的写作:来自专家的建议第11章 因果关系研究11.1 相关性并不代表因果关系11.1.1 对因果关系提问11.1.2 干扰因子:一个关于在线约会网站的例子11.2 OK Cupid的发现11.3 黄金准则:随机化临床实验11.4 A/B测试11.5 退一步求其次:关于观察性研究11.5.1 辛普森悖论11.5.2 鲁宾因果关系模型11.5.3 因果关系的可视化11.5.4 定义:因果关系11.6 三个小建议第12章 流行病学12.1 Madigan的学术背景12.2 思维实验12.3 统计学在现代12.4 医学文献与观察性研究12.5 分层法不解决干扰因子的问题12.6 就没有更好的办法吗12.7 研究性实验(OMOP)12.8 最后的思维实验第13章 从竞赛中学到的:数据泄漏和模型评价13.1 Claudia作为数据科学家的知识结构13.1.1 首席数据科学家的生活13.1.2 作为一名女数据科学家13.2 数据挖掘竞赛13.3 如何成为出色的建模者13.4 数据泄漏13.4.1 市场预测13.4.2 亚马逊案例学习:出手阔绰的顾客13.4.3 珠宝抽样问题13.4.4 IBM 客户锁定13.4.5 乳腺癌检测13.4.6 预测肺炎13.5 如何避免数据泄漏13.6 模型评价13.6.1 准确度重要吗13.6.2 概率的重要性,不是非0 即113.7 如何选择算法13.8 最后一个例子13.9 临别感言第14章 数据工程:MapReduce、Pregel、Hadoop14.1 关于David Crawshaw14.2 思维实验14.3 MapReduce14.4 单词频率问题14.5 其他MapReduce案例14.6 Pregel14.7 关于Josh Wills14.8 思维实验14.9 给数据科学家的话14.9.1 数据丰富和数据匮乏14.9.2 设计模型14.10 算算Hadoop的经济账14.10.1 Hadoop简介14.10.2 Cloudera14.11 Josh 的工作流程14.12 如何开始使用Hadoop第15章 听听学生们怎么说15.1 重在过程15.2 不再简单15.3 援助之手15.4 殊途同归15.5 逢山开路,遇水架桥15.6 作品展示第16章 下一代数据科学家、自大狂和职业道德16.1 前面都讲了些什么16.2 什么是数据科学(再问一次)16.3 谁是下一代的数据科学家16.3.1 成为解决问题的人16.3.2 培养软技能16.3.3 成为提问者16.4 做一个有道德感的数据科学家16.5 对于职业生涯的建议
使用说明
1、下载并解压,得出pdf文件2、如果打不开本文件,请务必下载pdf阅读器
3、安装后,在打开解压得出的pdf文件
4、双击进行阅读试读>
下载仅供下载体验和测试学习,不得商用和正当使用。
下载体验