
PS:知识兔分享下载的是尖叫青蛙14破解版,软件包内附带可解除软件所有使用限制的注册机,破解步骤按下文操作即可。
尖叫青蛙14破解版安装教程:
1、在知识兔下载解压,得到Keygen注册机和尖叫青蛙14源程序。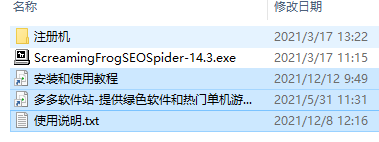
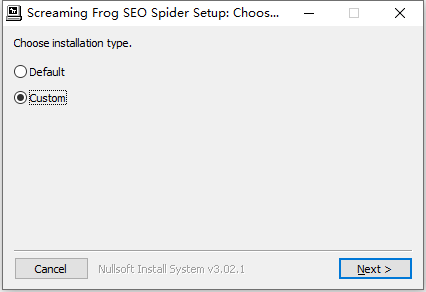
2、双击安装软件,选择custom自定义安装,点击next进行下一步。
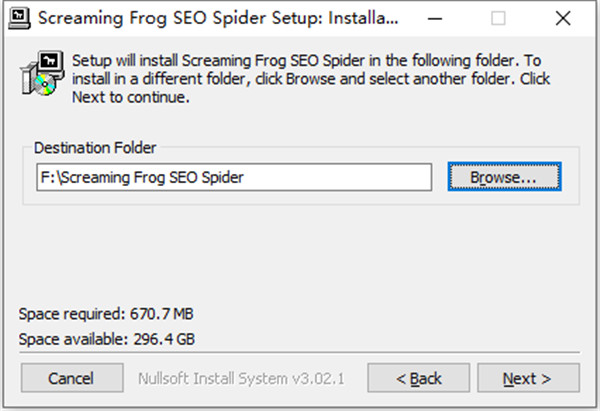
3、选择软件安装路径。
4、软件安装完成,退出导向即可。
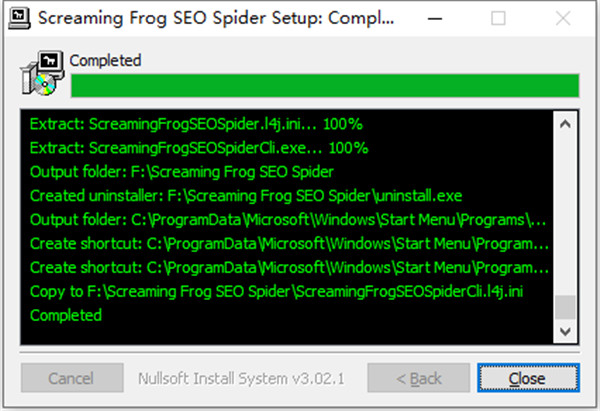
5、运行软件,系统会自动弹跳出升级框,不需要选择升级,然后选择licence下的注册按钮,运行Keygen文件下的注册机,将注册机里的用户名和秘钥填入注册的程序里,点击确定即可。
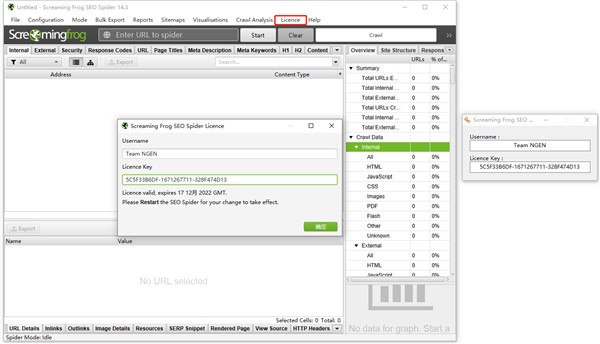
6、软件注册成功,以上就是尖叫青蛙14破解版的详细安装教程。
软件特色
1、查找损坏的链接立即抓取网站并找到损坏的链接 (404) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传要在站点迁移中审核的 URL 列表。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并找出网站中过长、过短、缺失或重复的页面标题和元描述。
4、发现重复内容
使用 md5 算法检查发现完全重复的 URL,部分重复的元素,如页面标题、描述或标题,并找到低内容页面。
5、使用 XPath 提取数据
使用 CSS Path、XPath 或正则表达式从网页的 HTML 中收集任何数据。这可能包括社交元标签、附加标题、价格、SKU 或更多!
6、查看机器人和指令
查看被 robots.txt、元机器人或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
快速创建 XML 站点地图和图像 XML 站点地图,对 URL 进行高级配置以包括、上次修改、优先级和更改频率。
8、与 GA、GSC 和 PSI 集成
连接到 Google Analytics、Search Console 和 PageSpeed Insights API,并在抓取中获取所有 URL 的用户和性能数据以获得更深入的洞察。
9、抓取 JavaScript 网站
使用集成的 Chromium WRS 呈现网页,以抓取动态的、富含 JavaScript 的网站和框架,例如 Angular、React 和 Vue.js。
10、可视化站点架构
使用交互式爬网和目录力导向图以及树形图站点可视化来评估内部链接和 URL 结构。
11、安排审计
安排抓取以选定的时间间隔运行,并将抓取数据自动导出到任何位置,包括 Google 表格。或者通过命令行完全自动化。
12、比较爬网和登台
跟踪 SEO 问题和机会的进展,并查看爬行之间的变化。使用高级 URL 映射将暂存与生产环境进行比较。
尖叫青蛙使用教程
1、开始爬行有两种主要的爬行模式。抓取网站的默认“蜘蛛”模式或“列表”,允许您上传要抓取的 URL 列表。
您可以通过将主页插入到“输入蜘蛛的 URL”字段并单击“开始”来开始常规的“蜘蛛”抓取。
 这将抓取和审核输入的 URL,以及它可以通过同一子域上页面的 HTML 中的超链接发现的所有 URL。
这将抓取和审核输入的 URL,以及它可以通过同一子域上页面的 HTML 中的超链接发现的所有 URL。爬取会实时更新,速度和完成和剩余的URL总数可以在应用程序底部查看。
您可以单击“暂停”,也可以随时“恢复”抓取。您还可以保存抓取并稍后恢复,稍后将详细了解保存。
如果您更愿意抓取 URL 列表而不是完整站点,请单击“模式 > 列表”以上传或粘贴 URL 列表。

2、配置爬网
您无需调整配置即可抓取网站,因为 SEO Spider 默认设置为以与 Google 类似的方式抓取。
但是,您可以通过多种方式配置爬网以获取所需数据。查看工具中“配置”下的选项,并参阅知识兔的用户指南以了解有关每个设置的详细信息。
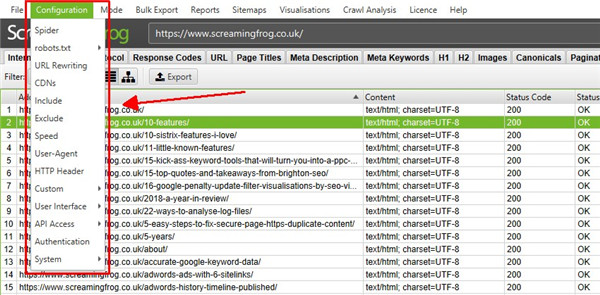
一些最常见的控制抓取内容的方法是抓取特定的子文件夹、使用排除(以避免按 URL 模式抓取 URL)或包含功能。
如果您的网站依赖 JavaScript 来填充内容,您还可以在“配置 > 蜘蛛 > 渲染”下切换到JavaScript 渲染模式。
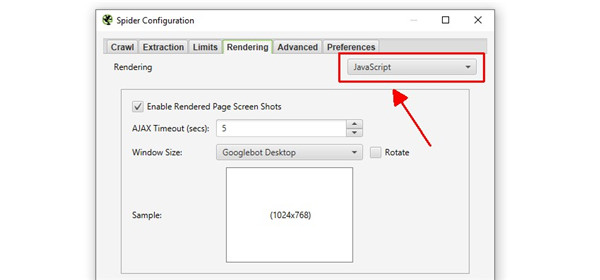
这意味着 JavaScript 被执行,SEO Spider 将在呈现的 HTML 中抓取内容和链接。
3、查看抓取数据
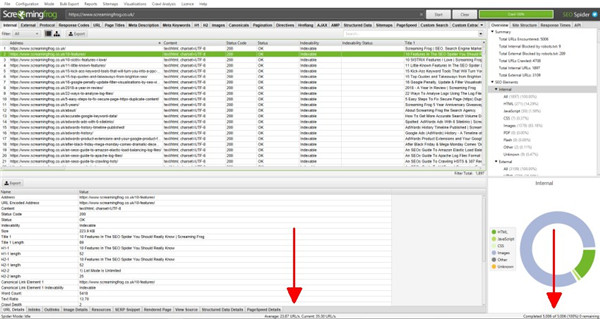
来自爬行的数据在 SEO Spider 中实时填充并显示在选项卡中。“内部”选项卡包括在对被爬行的网站的爬行中发现的所有数据。您可以上下滚动并向右滚动以查看各个列中的所有数据。
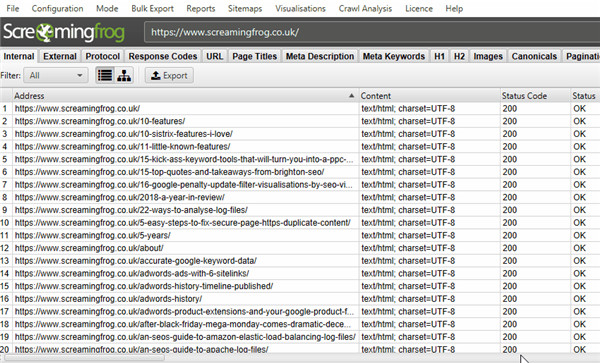 这些选项卡关注不同的元素,每个元素都有过滤器,可帮助按类型和发现的潜在问题优化数据。
这些选项卡关注不同的元素,每个元素都有过滤器,可帮助按类型和发现的潜在问题优化数据。例如,“响应代码”选项卡和“客户端错误 (4xx)”过滤器将显示发现的任何 404 页面。
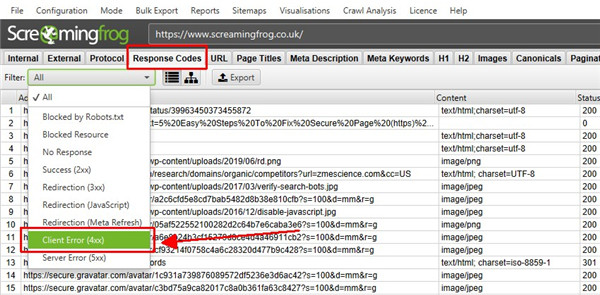
您可以单击顶部窗口中的 URL,然后单击底部的选项卡以填充下部窗口窗格。
这些选项卡分享有关 URL 的更多详细信息,例如它们的内链接(链接到它们的页面)、外链接(它们链接到的页面)、图像、资源等。
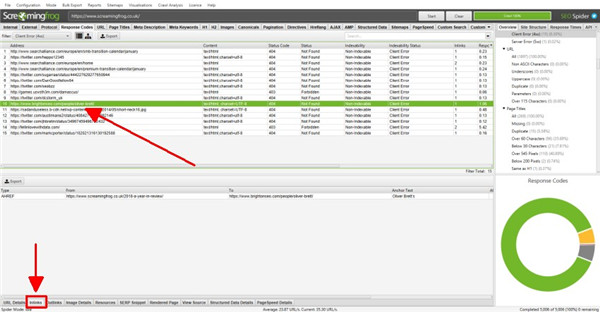
在上面的示例中,知识兔可以看到在抓取过程中发现的损坏链接的内链。
4、发现错误和问题
右侧窗口的“概览”选项卡显示包含在每个选项卡和过滤器中的爬网数据的摘要。您可以滚动浏览每个部分以识别发现的潜在错误和问题,而无需单击每个选项卡和过滤器。
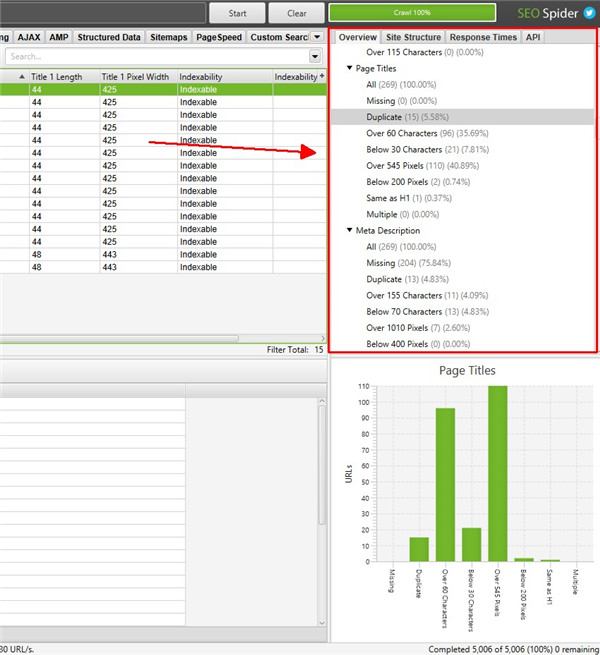
在大多数过滤器的抓取过程中,受影响的 URL 数量会实时更新,您可以单击它们直接转到相关选项卡和过滤器。
SEO Spider 不会告诉您如何进行 SEO,它会为您分享数据以做出更明智的决策。然而,“过滤器”确实分享了关于应该解决或至少在您的站点上下文中进一步考虑的特定问题的提示。
探索这些提示,如果您不确定选项卡或过滤器的含义,请参阅知识兔的用户指南。每个选项卡都有一个部分(例如页面标题、规范和指令)来解释每个列和过滤器。
5、导出数据
您可以将所有数据从爬网导出到电子表格中。只需单击左上角的“导出”按钮即可从顶部窗口选项卡和过滤器导出数据。
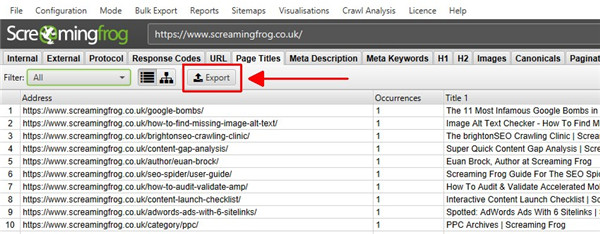
要导出下部窗口数据,请在顶部窗口中右键单击要从中导出数据的 URL,然后单击选项之一。
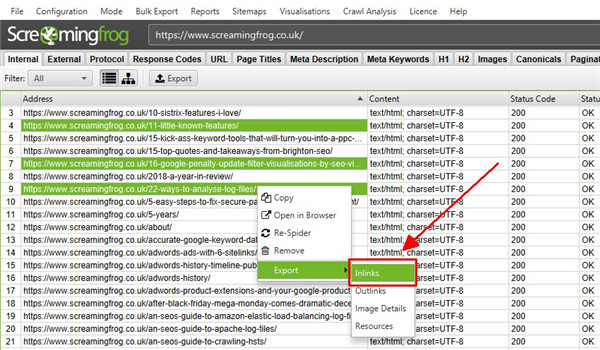
还有一个位于顶级菜单下的“批量导出”选项。这允许您导出源链接,例如带有特定状态代码(如 2XX、3XX、4XX 或 5XX 响应)的 URL 的“inlinks”。
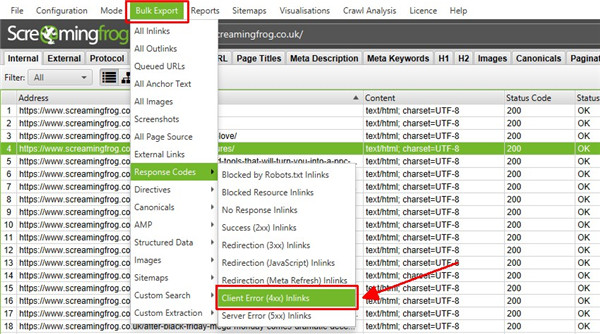
在上面,选择上面的“Client Error 4XX In Links”选项将导出所有链接到所有错误页面(链接到 404 错误页面的页面)。
6、保存和打开抓取
您只能使用许可证保存和打开爬网。在默认内存存储模式下,您可以随时(暂停或完成时)保存抓取并通过选择“文件 > 保存”或“文件 > 打开”重新打开。
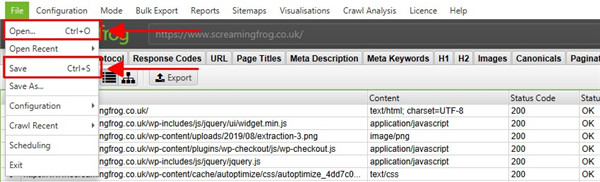
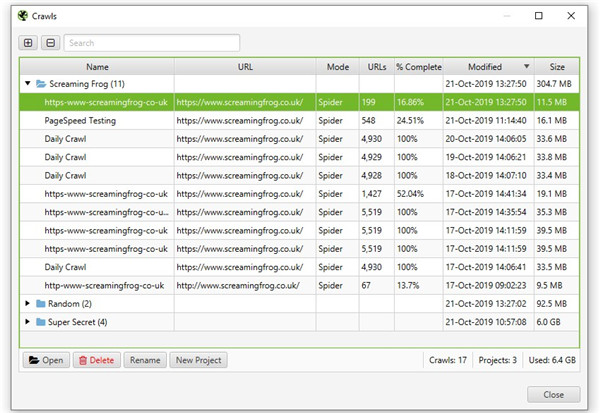
在数据库存储模式下,爬网会在爬网过程中自动“保存”并提交到数据库中。要打开爬网,请单击主菜单中的“文件 > 爬网”。

“抓取”窗口显示自动存储抓取的概览,您可以在其中打开、重命名、组织到项目文件夹中、复制、导出或批量删除它们。
软件亮点
1、查找断开的链接、错误和重定向2、分析页面标题和元数据
3、审查元机器人和指令
4、审计hreflang属性
5、发现重复的页面
6、生成XML站点地图
7、爬网限制
8、抓取配置
9、保存抓取并重新上传
10、自定义源代码搜索
11、自定义提取
12、Google Analytics集成
13、Search Console集成
14、链接指标集成
15、JavaScript渲染抓取
16、自定义robots.txt抓取>
下载仅供下载体验和测试学习,不得商用和正当使用。
下载体验