
软件特色
1、Nutch致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎2、每个月取几十亿网页
3、为这些网页维护一个索引
4、对索引文件进行每秒上千次的搜索
5、分享高质量的搜索结果
软件功能
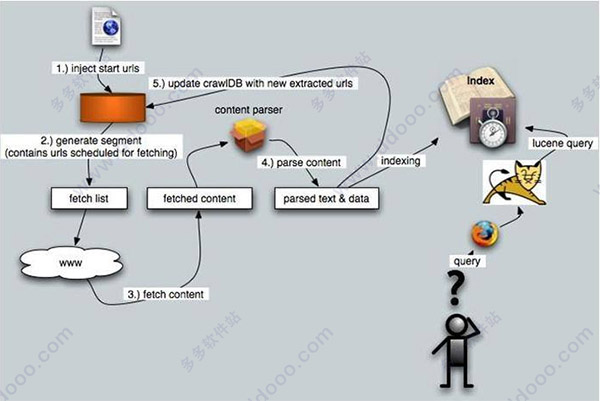
1、支持将起始URL集合注入到Nutch系统之中2、支持生成片段文件,其中包含了将要抓取的URL地址
3、根据URL地址在互联网上抓取相应的内容
4、解析所抓取到的网页,并分析其中的文本和数据
5、根据新抓取的网页中的URL集合来更新起始URL集合,并再次进行抓取
6、同时,对抓取到的网页内容建立索引,生成索引文件存放在系统之中
Apache Nutch使用教程
1、首先先运行软件,选择File -> Import Project ->选择apache-nutch-1.9文件夹,确定后选择Import project from external model(Eclipse)
2、一直点击next到结束,成功将项目导入project中去
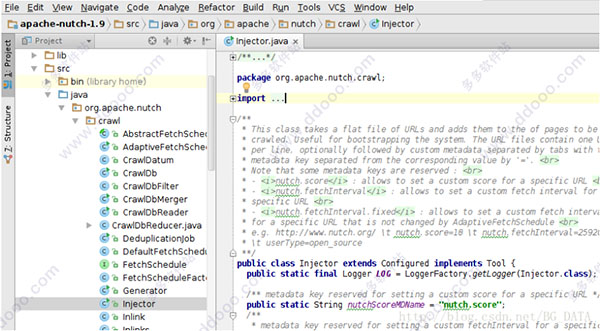
3、源码导入工程后,并不能执行完整的爬取。Nutch将爬取的流程切分成很多阶段,每个阶段分别封装在一个类的main函数中。在外面通过Linux Shell调用这些main函数,来完整爬取的流程。下面知识兔来运行Nutch中最简单的流程:Inject。知识兔知道爬虫在初始阶段,是需要人工给出一个或多个url,作为起始点(广度遍历树的树根)。Inject的作用,就是把用户写在文件里的种子(一行一个url,是TextInputFormat),插入到爬虫的URL管理文件(crawldb,是SequenceFile)中。
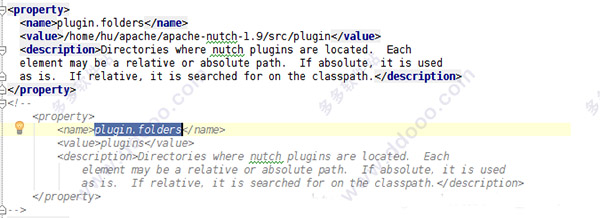
4、接下来知识兔按照Nutch默认的配置,需要修改Nutch的配置文件,为插件文件夹指定一个绝对路径,修改conf/nutch-default.xml文件内容,并且保存到工程中
5、接下来知识兔就可以开始对指定的网站的信息进行完整的爬取了
更新日志
Apache Nutch v1.9更新:1、增加了可爬取的数据类型
2、增加对Web爬虫的管理功能
3、解决了一些格式上的已知问题
4、修复了一些bug,优化了软件界面
5、优化了软件性能>
下载仅供下载体验和测试学习,不得商用和正当使用。
下载体验